Net als met (N)VARCHAR, vaak kies je gewoon lekker wat ruimer/groter zodat ‘het er altijd in past’. Tja dat denk je waarschijnlijk ook m.b.t. NUMERIC()?
Ik eerlijk gezegd ook, tot ik het volgende tegenkwam in een van m’n stored procedures:
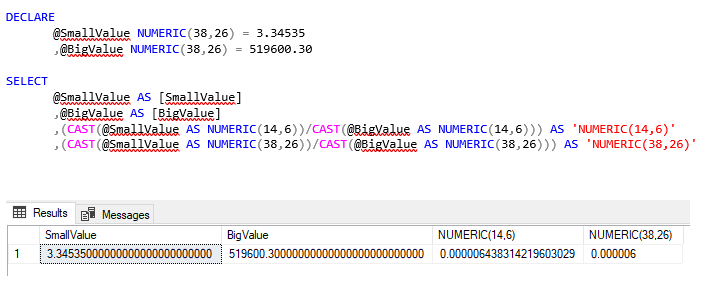
DECLARE
@SmallValue NUMERIC(38,26) = 3.34535
,@BigValue NUMERIC(38,26) = 519600.30
SELECT
@SmallValue AS [SmallValue]
,@BigValue AS [BigValue]
,(CAST(@SmallValue AS NUMERIC(14,6))/CAST(@BigValue AS NUMERIC(14,6))) AS ‘NUMERIC(14,6)’
,(CAST(@SmallValue AS NUMERIC(38,26))/CAST(@BigValue AS NUMERIC(38,26))) AS ‘NUMERIC(38,26)’
In het bovenste voorbeeld verlies je nauwkeurigheid, indien je dus kiest voor NUMERIC(38,36). Zo verdeelde ik bedrag X over alle Orders op basis van een ander attribuut en binnen Analysis Services kwam ik uiteindelijk op een totaalbedrag dat soms niet eens in de buurt kwam.
Nu hoop ik dat iemand het antwoord heeft op de vraag hoe dat dit komt? Ik heb online gezocht, maar kon zo snel geen reden vinden waarom SQL Server terugvalt op een precisie van 6 decimalen..
Mocht je werken met een hoge nauwkeurigheid, vergeet dan ook zeker niet om binnen je Tabular Model data te importen met (max) 15 decimalen:
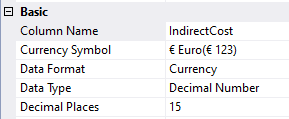
In de formatting van je Measures kun je alsnog ‘terug’ naar 2 decimalen, maar dan wordt er door DAX uiteindelijk wel gerekend met 15 decimalen precisie.
Ook dit heeft natuurlijk een trade-off en dat is het geheugen gebruik, dus alleen veel decimalen indien je dit ook echt nodig hebt 🙂
Nieuwsgierig naar de mogelijkheden van Azure en DevOps binnen uw organisatie?
Neem dan contact met ons op: clint.huijbers@monkeyconsultancy.nl
